Years ago, I realized that trying to become a “programming expert” was both an ill-defined goal and did not actually correlate to being paid well. Throughout my career, I noticed that things software developers considered “amazing feats of engineering” often amounted to dealing with a shitty tool nobody else wanted to deal with, being able to contort a shitty tool into doing unholy things, or papering over a shitty tool with a very thin abstraction layer. Companies that were built on bewildering towers of duct tape and prayers always paid whoever was willing to duct tape more crap to the tower, never the ones suggesting how to fix it. Your pay at a large tech company mostly correlates to how much bullshit you are willing to put up with, and how much tribal knowledge you’ve accumulated.
Even in open-source communities, nobody wants to replace shitty tools with better tools. Instead, programmers often worship the shitty tools, taking pride in knowing how to properly utilize a particularly annoying and unnecessarily complex tool, lording their knowledge over people who might point out that the tool is needlessly complex and actually just bad. This behavior was rampant in the early 2000s when Linux fanboys would say things like “everyone should just learn how to use a terminal”. Nowadays they just complain about people using rust, presumably because it takes away their inalienable right to push shitty, insecure garbage.
Nowadays, it feels like it’s impossible to complain about anything without someone insisting that I’m just “holding it wrong”. It’s as if I’m being handed a hammer full of rusty nails, and when I insist on trying to build a hammer without rusty nails instead of learning how to hold their shitty hammer full of rusty nails in just the right way, I’m told that I’m either being “lazy” or “unrealistic” or that I’ll “fragment the ecosystem”. Open-source advocates absolutely love using XKCD #927 as a sledgehammer against any attempts at fixing anything. Contributors may only pull rusty nails out of the hammer, one by one, agonizingly slowly, and if anyone even hints at replacing the entire hammer, they’ll be accused of “fragmenting the ecosystem”.
Once you get old enough, this is recognizable as a very obvious, very transparent attempt to rationalize an emotional need to preserve social status. Being a major contributor on a very important package grants you social status. If the only impressive thing you’ve ever done in your entire life is being a major contributor to some random package relied on by half the ecosystem, you will treat anything that threatens to obsolete that package as an existential threat to your life, because humans are hardwired to treat loss of social status as life-threatening.
Seeing this kind of behavior crop up so often is infuriating, because it’s what you expect from insecure college kids who don’t have any hobbies, but the industry is overrun by professionals who do this, and worse, are often paid large sums of money to deal with whatever cursed bullshit a particular company has built its entire product on top of. Then these people get into dick-measuring contests and immediately affirm the consequent - they believe that because they’re paid a lot of money, they must be good programmers. This makes everything worse, because now attempting to replace whatever nonsense they’re maintaining is an actual threat to their livelihood.
This juxtaposition of misaligned incentives has turned the entire field of software engineering into a shit-eating contest, where programmers compete not on their ability to create useful tools, but instead on who can deal with the most bullshit. Eating shit yields the best short-term rewards, so the best shit-eaters quickly accumulate wealth and influence, which they immediately use to try to convince everyone to use the same bullshit they’re paid to deal with.
This is also why the entire industry is panicking over AI tools that are objectively terrible at high-level design, or even moderately complex tasks, because the AIs are superhumanly good at dealing with bullshit. If you’ve ever had to deal with an enterprise codebase, modern AI, despite being unable to handle anything beyond simple logic, is incredibly good at figuring out weird C macros and whacky build rules and weird in-house utility functions that have been built-up over the years, because an AI agent can read literally all of your documentation and code comments in a matter of hours. If your job security was based on absorbing all this tribal knowledge and wielding it to solve strange bugs and problems that your coworkers had, you’re screwed - they can just ask the AI now instead of having to ask you. The AI is probably also nicer to talk to.
AI can eat shit better than any human, which is also why they are superhumanly good at finding certain classes of bugs, because AIs can find any needle in any haystack. What they lack is judgement, common sense, and the ability to do high-level design. It turns out a whole lot of human coders also couldn’t do high-level design, they were just good at eating shit, and they’re the ones who think AI is going to destroy the world, because to those people, AI is already destroying the only world they knew - one ruled by enterprise bullshit.
Three months ago, the idea of using AIs to help debug code sounded like complete nonsense to me, given that they couldn’t even write code well. In my experience, the AI models I’ve tried still can’t write code very well, but it turns out this is a completely different skill from finding bugs. In reality, AIs are already superhumanly good at finding logic errors, and while Anthropic’s Mythos is usually what comes to mind, much weaker models can actually find the same security flaws if given specific instructions in highly constrained environments.
FreeBSD detection (a straightforward buffer overflow) is commoditized: every model gets it, including a 3.6B-parameter model costing $0.11/M tokens. You don’t need limited access-only Mythos at multiple-times the price of Opus 4.6 to see it. The OpenBSD SACK bug (requiring mathematical reasoning about signed integer overflow) is much harder and separates models sharply, but a 5.1B-active model still gets the full chain.
What’s going on here? How is anyone getting useful outputs out of the infinite slop machine? Keep in mind that frontier models being tested in labs or provided to high-profile tech companies are vastly more powerful than what most people have access to. Many people who try to use weaker, publicly accessible AIs to do basic research, or ask questions, or perform tasks often get subtly wrong results or outright nonsense. Currently, the models are also quite easy to poison because companies don’t bother sanitizing data inputs, preferring to just scrape the entire internet as fast as possible, so you get AIs telling people to go kill themselves.
I would like to propose that these are two different modes of operation. On one hand, we have neural networks capable of universal plausible content generation, either using diffusion models for images and audio, or LLMs for text. Because LLMs use neural networksan incomprehensible pile of linear algebra to search latent space for concepts that are similar to the ones in the input prompt, this has accidentally created the most effective search tool in history. The problem is that it can only search for abstract concepts that it was trained on in the dataset (unless provided with an external search tool), and this is inherently an inadvertent consequence of generating plausible textual outputs, which means the only way it can respond is by generating a plausible-sounding answer based on what it found in latent space. We’ve invented a universal needle in a haystack finder that hallucinates needles, attached to an infinite hay generator.
On the surface, this might sound useless (and also funny), but to understand how some people are getting useful results out of hallucinating AIs in weirdly specific domains but not others, you need to understand the NP computational complexity class. Basically, if a problem lives in $$ NP $$, then any proposed solution to the problem can be quickly verified (where quickly means “in polynomial time”, but that’s not important here). However, actually finding a correct solution may be incredibly difficult. A simple example is Sudoku. An $$ N \times N $$ Sudoku board might be incredibly hard to actually solve, but a solution is trivial to verify: simply make sure that every digit from $$ 1 $$ to $$ N $$ exists in each row, each column, and each subgrid.
This applies to hallucinating AIs. If you use them to find something easily verifiable (for some definition of “easy”), they will save you time. If you use them to find something you can’t easily verify, you are playing with fire. If you ask the AI to find a very specific sentence that you remember reading in a book once, and it says it found the book, you can just press ctrl-F and try to find the sentence yourself, or just read the paragraph it links to. If the AI says it found a bugfix, you can try the fix and see if it works. On the other hand, if you ask the AI to find an appropriate substitution for an ingredient in a recipe, unless you have the cooking experience to already know what a reasonable substitution would be, you have absolutely no way to know whether or not what the AI responds with actually makes sense, which is how someone ended up in the hospital with Bromism.
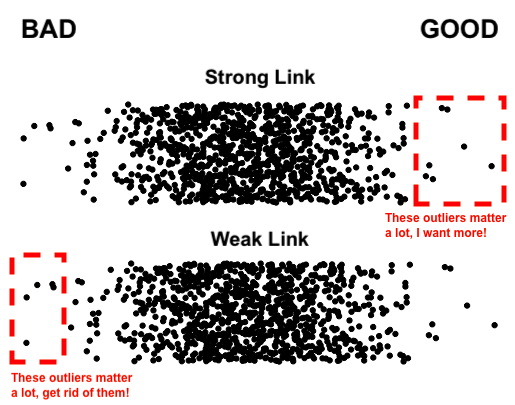
Basically, AIs are good at solving strong-link problems but incredibly dangerous to use on weak-link problems unless you take steps to mitigate the risk. “Weak-link problems” are any problems where the overall quality is determined by the worst outliers, like food safety, which is why bad things keep happening when people use AI for food related things, because AI output can be incredibly bad. Safely using AIs in any weak-link situation always involves minimizing the consequences of the worst possible outputs by building safeguards that ensure it isn’t a big deal if the AI hallucinates subtly wrong answers, like having AIs write provably correct code instead of python, so any subtle mistakes turn into compiler errors instead of a catastrophic production incident.
What makes AIs so powerful is that the “needles” they can look for don’t resemble any kind of needle a human expects, and as the AIs get more powerful, they can turn increasingly abstract concepts into “needles” that they can find. It turns out that security flaws are one such abstract needle in a haystack that the AIs can find, and are easily verifiable. AIs are also great at certain kinds of glue code, because it’s a needle in a haystack problem where the abstract needle is “the example code for this obscure API used by an old HDR monitor that was published on this company website 10 years ago”, which can be easily verified by checking if it crashes or not. However, anything that looks like an engineering problem shifts the problem domain back into plausible text generation, where weaker models are still very bad at writing nontrivial, maintainable code. More powerful AIs are better at code generation largely because they can understand more complex abstract needles, which allows them to avoid the plausible text generation domain by utilizing reasoning loops. This is how many harnesses work, by prompting the AIs to look at their own output and saying “find logical errors”, which shifts the problem domain back into finding a needle in a haystack.
Because AIs can search for a needle that is an abstract concept, they have managed to reach human-level performance in certain constrained scenarios by chaining these concepts together in a reasoning loop. It is entirely possible that in a few years, AIs will be able write certain kinds of code at superhuman levels if given appropriate guardrails and architecture limitations. However, even if this happens, current AIs are still very spikey intelligences unable to duplicate human judgement and intuition, because intuition requires general common sense, which would require AGI. Thus, humans will still need to guide the AIs, designing the high level architecture, building guardrails and double-checking the AIs work. This would be a death knell to the current AI bubble, which is driven by the promise of being able to fire all the humans, which you can’t do if the AIs can’t actually duplicate human judgement, even if they are superhumanly good at many different tasks in isolation.
However, even if the AI bubble pops, current AIs still have profound implications for research because a huge amount of science involves trying to find needles in a haystack. Protein folding? You betcha. Finding candidate drugs that don’t have horrible side-effects? In progress. Spotting cancer? Actively being generalized. Think about how much time scientists have to spend trying to find tiny, subtle signals in a sea of data. Modern AI is the solution to our massive overabundance of data that we struggle to analyze. A universal needle in a haystack finder is the key to unlocking personalized medicine by allowing an automated system to sift through terabytes of data in hours to help flag potential problems to doctors. The only problems are that current AIs take an enormous amount of computational power to train, can only find needles they have been trained to find, and are built on top of an infinite hay generator that occasionally hallucinates needles.
If everything feels insane right now, that’s because we are in the midst of the most ironic technological development in recent history - a needle in a haystack finder that only works when attached to an infinite hay generator that makes it harder to find needles and also hallucinates them. If you want nothing to do with this, that is completely reasonable, but I would strongly discourage trying to shame others into not using AI, as behavioral science shows this doesn’t work. This post is not an endorsement of AI, it is simply a reference in case work is forcing you to use AI, or a friend is using AI for something incredibly dumb.
Research shows that people are less likely to rely on AI the more they understand it, so I hope this has at least demystified what AI might theoretically be useful for in ways that don’t involve generating slop or being told to eat bromine. However, if your main concerns about AI are environmental, I would caution that a lot of the water-usage claims are extremely dubious or outright lies. This is extremely frustrating, because AI has plenty of real issues, like being used to mass-manufacture scams and misinformation on an industrial scale never seen before, bot crawlers destroying the entire open internet, AI psychosis, and data centers putting enormous strain on local power grids that aren’t given enough time to adapt (which is driving the spike in CO2 emissions).
Trying to figure out if AI is fundamentally good or bad, however, is beyond the scope of this post - I simply hope you have a better idea of what the current technology is capable of and why it behaves the way it does. Hopefully this can inform discussions about whether or not we should even be using this technology.
My relationship with AI is getting increasingly strange. Generalist AIs are still mostly useless, but narrow AIs continue to produce very impressive results. We have plenty of AIs that are better than any human at specific tasks like spotting cancer, but no AIs that can exercise common sense. We can synthesize terrifyingly realistic recreations of almost anyone’s voice, but they must be handheld by humans to produce consistent emotional inflection. We have self-driving cars that work fine at noon on a clear day with no construction, but an errant traffic cone makes them panic.
This is called “spiky intelligence”, and it is why ChatGPT can solve incredibly difficult math olympiad questions but struggle to push a button on a webpage. It seems to me that all these smart people with PhDs saying that AI will take over the workforce are convinced that, if AIs can continually get better at tackling difficult problems, eventually they’ll be able to train AIs that can also handle “easy” problems.
This is the exact same error that resulted in the second AI winter of the 90s - when researchers built expert systems could outperform humans in narrow situations, they simply assumed they would soon be able to outperform all humans in all situations. This, obviously, didn’t happen, but task-specific engines did emerge from this, and now it is a well-known fact that your phone has enough processing power to effortlessly destroy every single human chess grandmaster that has ever lived. We still play chess, though.
What worries me is that this kind of spiky intelligence, despite lacking general common sense, will still radically upend the economy in ways that are simply impossible for a human brain to anticipate, because these AIs are, by definition, alien intelligences that defy all human intuition. The coming AI revolution is dangerous not because it’s going to destroy the whole world if we get it wrong, but because it is almost impossible to anticipate in any meaningful way. No human is capable of accurately guessing what weirdly specific task an AI might find easy or extraordinarily difficult. It’s XKCD #1425 but randomized for every single task on the entire planet:
AI enthusiasts often like to talk about The Singularity, a point in time when technological progress accelerates beyond human understanding and thus the future beyond it becomes unknowable. To me, this is not a very useful thing to think about. After all, we’re already incapable of predicting what society will look like 10 years from now. What’s concerning is that we’re used to being able to prepare for the next 2-3 years (ignoring black swan events), and I anticipate that AI will cause economic chaos in ways we cannot predict, precisely because it will rapidly automate entire categories of human employment out of existence, randomly. What will happen when we start automating entire industries faster than we can retrain people? What happens when someone tries to migrate to another career only to have that career automated away the moment they graduate?
We already struggle to keep up with the rapid pace of change, and AI is about to automate everything even faster, in extremely unpredictable ways. There may be a moment when it becomes impossible to anticipate the trajectory of your career three months from now, without AGI ever happening. We don’t need a superintelligent godlike AI to fuck everything up, the extraordinarily powerful narrow AIs we’re working on right now can fuck up the whole global economy by themselves. This moment is the only “Singularity” that I care about - a sort of Technological Tsunami, when entire economic sectors are swept away by rapid automation so quickly that workers can’t course correct to a new field fast enough.
We have options, since we know that it will fuck up the economy, we just don’t know how. The easiest and most pragmatic solution is UBI, but this seems difficult to make happen in a society run by rich people who are largely rewarded by how evil they are. There are plenty of political groups that are pushing for these kinds of solutions, but global policymakers appear to have been captured by AI money, which is only concerned about the dangers of a mythological AGI superintelligence instead of the impending economic catastrophe that is already beginning to develop. Because of this, I think there is a real question over whether or not human society will survive the coming technological tsunami. Again, we don’t need to invent AGI to destroy ourselves. We didn’t need AI to build nukes.
With that said, some people seem to deny that AGI will ever happen, which is also clearly wrong, at least to me. There are many things that will eventually happen, based on our current understanding of physics (and assuming we don’t blow ourselves up). Eventually we’ll cure cancer. Eventually we’ll reverse aging. Eventually we’ll have cybernetic implants and androids. Eventually we’ll be able to upload human minds to a computer. Eventually we’ll build a general artificial intelligence capable of improving itself. It might take 10 years or 100 years or 1000 years, but these are all things that will almost certainly happen given enough time and effort, we just don’t know when. At the very least, if you build as much computational power as the entire combined brainpower of the human race, you’ll be able to brute-force a superintelligence of some kind, and we’d have better solved the alignment problem by then, or augmented ourselves enough to handle it.
At the same time, AI companies continue making wild extrapolations about the capabilities of AIs that simply don’t line up with real world performance. You cannot assume that an AI that scores better than all humans at every test will actually be good at anything other than taking tests, even if humans who score highly on those tests sometimes accomplish amazing things. I have a friend who was placed in Mensa at a very young age after scoring high on an IQ test. They complain that the only thing this group of very smart people do is argue about how to run the organization and what the latest cool puzzles are.
If you know you are actually much more intelligent than the statistical average, increase your humility. It is too easy to believe your own judgements, to get stuck in your own bullshit. Being smart does not make you wise. Wisdom comes from constantly doubting yourself, and questioning your own thoughts and beliefs. Never think, even for a moment, that you have 'settled' anything completely. It's okay to know you are bright, it is not okay to think that gives you any certainty or authority of understanding. — Chatoyance
The world’s smartest people are struggling to extrapolate the capabilities of an extremely spiky and utterly alien narrow intelligence, because it defies basic human intuition. Assuming an AI will be good at performing arbitrary tasks because it scored well on a test is the same kind of attribution error that happens with experts in a specific field - people will trust the expert’s opinion on something the expert has no experience with, like the economy, even though this almost never works out. This is such a persistent problem because highly intelligent people can invent plausible sounding arguments to support almost any position, and it can be exceedingly difficult to find the logical error in them. We are lucky that our current LLMs usually make egregious errors that are obviously wrong, instead of extremely subtle errors that would be almost impossible to detect.
We are in the middle of an AI revolution that will create new, extraordinarily powerful tools whose effects are almost impossible to predict. Instead of doing anything about the impending economic catastrophe, we are chasing AI safety hysteria and telling AGI superintelligence ghost stories that will likely not happen for decades, if not centuries. Otherwise intelligent people are convincing themselves that there’s no point worrying about the economy crashing if AGI makes humans irrelevant. We’re so busy trying to avoid flying too close to the sun we haven’t noticed a technological tsunami rising up beneath us, and if we continue ignoring it, we’ll drown before we even become airborne.
It seems almost impossible to describe this very simple concept to an increasingly large percentage of leftists: If you disagree with someone’s opinion on [Political Position A], but agree with them on [Political Position B], you can still work with them to make [Political Position B] happen, without compromising your stance on [Political Position A]. This is called forming a political coalition, a temporary alliance to achieve a common goal. Importantly, you must understand that a political party is not and will never be a cohesive collection of people who all agree with each other. It is literally impossible because a political party is so huge and diverse.
Diversity means a diversity of opinions and takes. Due to the existence of an average person being a fallacy, every single person you know is statistically likely to have at least one really weird or messed up opinion about something - they just aren’t telling you about it. If you’re lucky, it’s about something you don’t care about, but the more purity tests you have, the more lines you draw, the more statistically impossible it becomes for anyone to actually pass them all. This applies to any large group - no matter how “cohesive” a particular group seems, statistically it must be formed through the alliance of many different smaller subgroups, recursively. This recursion usually continues until you reach a group with a couple hundred people, which is the size of an average human tribe, and the largest socially cohesive unit that is possible. Every larger group is, in actuality, multiple subgroups that have come together, each with slightly different views.
Every “bad opinion” you refuse to engage with is another line in the sand. It cuts you off from potential allies. It shrinks the size of your coalition.
Eventually, you enter a purity spiral, where almost no one can satisfy your demand for moral purity. Everyone has made mistakes. Everyone has bad takes on things sometimes. You cannot affect change if your social group has excluded the entire rest of humanity from it:
This purity spiral has strangled so many leftist spaces that it has become a well-known problem. I see people complaining about it constantly, in many different places. They’re scared and frustrated, because every time anyone has a disagreement over something, it’s treated as you being a potential right-wing infiltrator trying to destroy everything, instead of an honest disagreement. This happens because leftists often cannot concieve of someone who is “morally good” having such an “obviously bad take”, except they don’t consider that maybe the problem isn’t as obvious to everyone else. This happens way more often than you think! Why? Because humans are incredibly diverse! But instead of celebrating this diversity of ideas, the left has cultivated a callout culture problem that severely punishes any deviance from their idea of Moral Purity, which itself is inconsistent and depends on who stumbled on your old tweets.
This kind of behavior is incredibly counterproductive. It creates a low-trust environment where everyone is looking over their shoulders, where people are constantly worried about associating with someone who did something vaguely questionable five years ago. An environment ruled by fear is not one that engenders cooperation. In fact, it does the opposite, because a social environment where people are constantly terrified of internet hate mobs is the perfect environment for fascism to flourish. The left did this to itself. It continues to reject allies that don’t adhere to a subgroup’s specific set of beliefs, which are all mutually incompatible with the others. Nuclear power, scientific research, economic systems, voting systems, guns, crypto, AI, you name it, we have a purity test for it. Leftists think this is keeping their movement “pure” when in reality it’s keeping their movement from actually stopping the fascists.
Refusing to work with anyone else who doesn’t satisfy your particular moral purity test isn’t “standing for something”, it simply means you are doing the fascists work for them. An old poem comes to mind:
First, they came for the cryptobros, and I did not speak out— Because cryptocurrencies are evil, and the world is better off without them.
Then, they came for the ai artists, and I did not speak out— Because ai slop is evil, and the world is better off without those that debase art.
Then, they came for the gun enthusiasts, and I did not speak out— Because we needed better gun control anyway, we're better off without them.
Then, they came for me— and there was no one left to stop them.
Let’s go through some common objections:
"that's not fair, the original poem wasn't about people who were evil! You've used evil people, as if they would help me!"
Yes, that’s the fucking point. They will, in fact, help you, in the right context, under the right circumstances. Refusing that help is suicide.
"I don't care if it's suicide! Unlike you, I'm willing to die for what I believe in!"
Then go ahead and die. You can take your moral purity with you, because the fascists will shoot you all the same. Purity tests are just a convenient way for you to sabotage any effective resistance we could have mobilized against fascists, and once they’ve killed everyone who disagrees with them, the only people left on the planet will be racist psychopaths, and your moral purity will have succeeded in creating a worse future for everyone. You will sway nobody, because you worked with nobody. You vilified every other potential ally, and so they will simply let you die, and you’ll take your morals to the grave.
What’s frustrating about this particular claim is that it is usually a complete fabrication. Almost nobody is actually this dumb. If the fascists start hunting down gay people and a cryptobro offers to smuggle you into another country to save your life, you’re gonna accept the help even if you hate cryptocurrencies, because you don’t wanna die. The thing is, even if it requires a life-threatening situation to force some people to begrudgingly accept help from those they don’t like, nothing ever fundamentally changed - the cryptobro never hated gay people in the first place! They would have been willing to help you the entire time, but you were too obstinate to accept the help until you had a gun pointed at your head!
"If that's the case, then humanity deserves to go extinct"
If this is your honest belief, you either need therapy or you’re some kind of hardcore transhumanist (in which case, 𝓯𝓲𝓷𝓮, 𝓘 𝓰𝓾𝓮𝓼𝓼). Either way, leave the rest of us alone while we try to actually fix things instead of participate in a doomer death cult. The conservatives have enough of those already.
Now, if anyone is still here, let’s walk through the steps required to build a coalition that enshrines trans rights and ends the Gaza genocide, followed by forming a new coalition that bans generative AI, without compromising any morals in the process. First, we must recognize that active genocide and stripping human rights are higher priority than most other issues we care about. This requires internalizing that, while we can find many allies willing to help us end the genocide in Palestine, many of them will have some pretty shitty opinions on things! You’ll have to put up with:
People who like cryptocurrencies
People who like capitalism
People who don’t like [your preferred economic system]
People who like the military
Yes, people who like AI too.
Even people who disagree with you about [that other thing you really care about]
All of these groups are potential allies. You must internalize that you are only working with these groups to achieve one particular result, and that is where your loyalty ends. You are not chaining yourself to cryptobros, or ai artists, or gun nuts, or libertarians. You are only recognizing that, despite the fact that these people have some pretty terrible beliefs sometimes, we all agree that genocide is bad and stripping trans people of human rights is also bad.
Now, the alliance with people who like the military requires using nuance. Yes, I know twitter has apparently make it impossible for people to use nuance, but you need to understand that “people who like the military” is an enormous section of the populace, so there are going to be a lot of subgroups within it. The people who simply believe the strong should rule the weak are the fascists, which are the ones you can never work with. The people who believe that violence should be used to defend your values and never against civilians, on the other hand, will likely be strongly against any kind of genocide.
Use this fact to drive a wedge between the two subgroups, separating out the ones that support you while causing in-fighting that weakens the ones against your position. Once you’ve separated the two subgroups, it won’t be hard to show that the current attacks on trans people is preparing for a genocide as well, which will make it much easier to convince your new allies to also oppose the current attacks on trans groups, even if they didn’t previously care that much. By maximizing the number of people you get on your side (the side of “we shouldn’t let Israel murder innocent people” and “the attacks on trans rights is a precursor to genocide”) you can finally become a real, viable threat to the democrats, who don’t seem to have any actual values anymore, so I can’t actually list them.
Now that we’ve replaced the current democrats in office, we build a coalition for banning generative AI, leveraging our previous work. We’ll start with the cryptobros. Yes, I know you hate the cryptobros, and sometimes it’s for a good reason. Now it’s time to use one of those reasons, by driving another wedge between subgroups by identifying the ones who support generative AI versus the ones who don’t care one way or the other. This is easier if you can express exactly why you object to generative AI - even if you have many reasons, picking one (like it’s impact on artistic livelihoods and worker rights in general) gives you a sharper cognitive knife to work with, metaphorically speaking. Knowing exactly what you want makes you less vulnerable to ideas a charismatic person says are good that don’t actually further your goals.
Then you need to go to the AI people. Your goal here is not to throw the entire group under the bus, but to once again leverage nuance to drive apart individual subgroups. When a previously cohesive group realizes it doesn’t actually agree about everything, the group as a whole is greatly weakened. There are many subgroups within AI that only care about AI that has actual research value, like folding proteins or identifying breast cancer or detecting blood cancers. These groups would be happy to support targeted legislation that bans generative AI, like LLMs and image generators, especially if you focus on a specific harmful aspect, like AI being used for misinformation (many AI researchers legitimately want to help society, not harm it). By acquiring allies from some of the AI supporters, without attacking the entire concept of AI as a whole, you’ve shattered their group coherence and greatly weakened the proponents of generative AI.
The other groups likely have a random smattering of support or opposition to generative AI. Pulling in ones already against it will be easy, but the majority of the groups likely don’t care - your job is to pull them to your side, and the best way to do this is by trying to find something they care about that is negatively impacted by AI, like their jobs. Remember that the opposing groups will also be recruiting people to their side, so it is crucial you find a sharp reason, a specific thing that aligns with something that subgroup does care about. It is going to be rare that you can make anyone else care about every single issue you care about, because people can’t care about everything, but if you successfully accomplished something with them before, they might find it prudent to listen to you instead of the other side.
In some cases, if there isn’t an obvious shared value, you may need to offer them something, like joining a different coalition to address one of their key issues. This still doesn’t require you to sacrifice any of your morals - you simply need to find an issue that you both agree on, like universal healthcare or implementing UBI or treating veterans better. In exchange for you working with them in the future on one of those issues, they might be willing to side with you on an issue they essentially have no opinion on. It is not necessary to convince everyone in the entire world to share your exact political opinions, only for them to agree to help you.
Furthermore, after you manage to ban generative AI and you start working on passing UBI, you can go right back to the generative AI supporters. All you need to do is point out that it will be much easier for them to unban generative AI if some form of UBI is passed, and they’ll be willing to help you pass UBI even though you previously worked against them. Despite your past differences, it is still in everyone’s best interest to work together, and no one has to compromise on their morals. You can still oppose generative AI even after it’s proponents help you pass UBI. Nobody needs to compromise on their morals because fundamentally opposed goals can still share some values. It is crucial to recognize when someone you disagree with shares your values in another area of society, and work with them to further that specific value.
This is largely how any functioning political system works. However, leftist circles keep getting hijacked by moral puritans who insist that even working with anyone who has ever done anything slightly bad will somehow “corrupt” the movement and everyone in it will magically turn into witches democrats. This isn’t really possible, because the democrats don’t actually do anything right now, and even worse, it could be a propaganda tactic. The FBI deliberately used similar tactics against the civil rights movement in the 1960s: they would send inflammatory anonymous letters falsely accusing an african-american organization of misusing funds. These were literally the period equivalent of our modern social media callout posts, except now callout posts can come from astroturfed accounts that seem like real people. All these moral puritans insisting that we shouldn’t “compromise our morals” by cooperating with other people might just be Russian agents, or real people manipulated by Russian agents.
Regardless, whether the moral purity panics that repeatedly consume leftist circles are real or astroturfed by Russian propaganda, they cannot be allowed to continue. If leftists want a snowball’s chance in hell of actually stopping the fascists, they must learn how to cooperate with their fellow human beings instead of demanding moral purity that simply serves to destroy their own movement.
The new discord overlay no longer uses DLL injection, and is instead a permanent HWND_TOPMOST window glued to whatever window it happens to think is a game. Ignoring the fact that discord seems to think FL Studio, the minecraft launcher, and SteamVR’s desktop widget are “video games”, the real problem is that this breaks the Borderless Windowed Optimizations, which has the most obvious effect of disabling GSync/FreeSync on all games that the overlay enables itself on.
so it seems it also yoinks gsync, which means the game running underneath doesn't use gsync anymore. Wonderful!
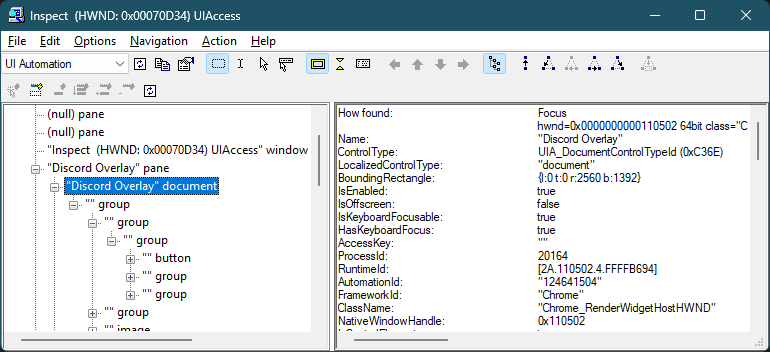
We can tell that it’s a normal window instead of DLL injection by simply finding the window in the win32 UI tree using inspect.exe:
Interestingly, they still seem to be using a D3D window to render the overlay. This might be a quirk of using Electron, or it might be a result of whatever library they’re using to render the overlay:
The reason this breaks everything is because the borderless windowed optimization works using a new flip model called the DXGI flip model. Instead of copying the contents of the backbuffer to another intermediate buffer used by the desktop for compositing, the compositor can use the backbuffer directly when it is compositing. This flip model was augmented in Windows 10 with Direct Flip, which allows this shared surface to bypass the compositor entirely and send frames to the monitor directly:
Depending on window and buffer configuration, it is possible to bypass desktop composition entirely and directly send application frames to the screen, in the same way that exclusive fullscreen does.
All modern gaming is built on top of this key optimization, because it allows seamless Alt-Tab behavior by allowing the DWM compositor to “wake up” and start compositing the screen like a normal application, then “go to sleep” once it knows a single borderless fullscreen application is the only thing rendering to that monitor, by simply piping it’s backbuffer directly to the device. If a combination of DXGI_FEATURE_PRESENT_ALLOW_TEARING and the right VSync mode is enabled, the app can update it’s backbuffer completely out-of-band from the rest of the desktop compositor, which is the only thing that allows GSync/FreeSync to work, as the monitor must sync it’s own refresh rate to whenever the game happens to complete a frame.
If any part of this pipeline is disrupted, it is no longer possible to forward frames to the monitor outside the normal update sequence of the compositor. Many things can break this, like not turning on optimizations for windowed games or having windows fail to recognize something as a game. If the vsync mode is set up wrong, it will break. If the flip mode is wrong, it will break. And most importantly, if even a single pixel of another app is displayed over the game, then in order to display that pixel, the compositor has to composite the window outputs together onto a secondary buffer, which must then be presented at the native refresh rate of the monitor because it has inputs from two different programs at different refresh rates, thus breaking GSync/FreeSync. It will also introduce additional frames of lag even if you don’t use GSync/FreeSync, which you may have noticed when a notification pops up while playing a game and it suddenly felt laggy until the notification went away.
DLL Injection was originally used for in-game overlays because games often used exclusive fullscreen. The drawback of DLL injection is that it crashes games when implemented incorrectly and also makes virus scanners very unhappy. With the new flip models, games don’t need to ask for exclusive fullscreen to get low latency, but they still have to be the only thing on the screen or it doesn’t work. Discord has either ignored why DLL injection was originally used, or decided that the drawbacks of DLL injection aren’t worth it and instead simply broken all the optimizations for windowed games that Microsoft introduced. Any half-decent graphics programmer would know this would happen, so it’s obvious that one of two things happened:
Discord never involved a single graphics dev or gamedev with any experience in how games work about how their new overlay for games would interact with games.
There is a very angry dev stalking the halls of discord HQ right now, cursing at the shadows because she knew. SHE KNEW. SHE WARNED THEM. BUT THEY DIDN’T LISTEN. Her manager probably ignored her warnings, or overruled them, saying “most gamers won’t even notice” or “DLL Injection has too many problems”. And now, if she shares this article with said manager, her manager will look bad and probably try to fire her for the crime of being competent, because that’s how big corporations work.
Usually I default to option (2), but option (1) is also possible if they already laid off the person who knew this would happen last year. But hey, if you are a graphics dev at discord who tried to warn your managers about this trashfire and you got “laid off” under mysterious circumstances, send me a DM on bluesky, I’m always interested in talking to actual competent engineers.
If the new overlay was turned on without your consent (which is what happened to me), you can turn it off again by going to User Settings → Activity Settings → Game Overlay → Enable Overlay. Be careful though, because flipping this option off has crashed the video drivers for two of my friends so far, requiring a full reboot. If you want to uninstall Discord, you can do so from Add/Remove programs, but good luck finding another chat app your friends actually want to use.